library(tidyverse)
read_lines('dat/story.txt')[1:5] |>
stringr::str_wrap(width = 50) |>
paste(collapse = '\n') |>
paste('...') |>
cat()
## Title: Dax Ironfist – The Reluctant Inventor
##
## Dax Ironfist let out a frustrated grunt as a
## spark flew from his latest creation, a small,
## gear-driven automaton designed to assist with
## forging. The stout dwarf wiped soot from his brow,
## his thick fingers carefully adjusting a valve
## on the automaton's chest. "Blasted thing," he
## muttered, tightening a bolt.
##
## His underground workshop, carved deep into the
## rocky heart of the mountain, was cluttered with
## gears, wrenches, and half-finished inventions. Dax
## had no interest in adventure—he had sworn long ago
## to let others chase glory while he built marvels
## in the safety of his forge. But fate, as it turned
## out, had other plans. ...4 Structured Output
In this chapter, we continue to talk about {ellmer}. You see, {ellmer} still has a pretty cool trick up its sleeves. And that trick has to do with structured output. Namely, {ellmer} (or rather the LLMs it talks with) allows you to extract data from unstructured texts in a structured format.
That’s huge! One of the most fundamental problems with regular prompting is that you can never be sure that you get output in the form that you wish. But for these kinds of situations, OpenAI and other vendors nowadays allow you to use so-called “structured output”.
And the best part: {ellmer} has built-in functionalities that allow you to use this structured mode really easily. In this chapter, I’ll show you how. And as always: There’s a video associated with this book chapter:
4.1 A ground truth
To test the structured output, we first need some data that we can extract things from. So let’s do something fun. Let’s come up with a little hero story (yes these details are absolutely GPT generated):
- Description: Dax Ironfist is a stocky, gruff dwarf with soot-covered hands, a thick brown beard, and a pair of goggles perpetually resting on his forehead. He despises adventure but is an unmatched engineer, constantly tinkering with mechanical inventions in his underground workshop.
- Journey: When his latest creation, an experimental automaton, malfunctions and escapes, Dax is forced to leave his comfort zone and track it down. His pursuit takes him into an ancient dwarven ruin filled with dangerous traps, where he meets a young adventurer who needs his expertise. Through their trials, Dax realizes that his skills can help more than just himself.
- Lesson Learned: Innovation isn’t just about personal success—it’s about using one’s talents to improve the lives of others.
What a beautiful character! Now we can let GPT generate a multi-page story that involves these details. This little stunt probably cost me 10 cents or so in GPT tokens. But it’s worth it. We now have something that we can ask GPT.
Anyway, I have saved this story in a file called story.txt:
Here, I’ve only printed the first few lines of the story. If you want to read the full story, you can do so here.
4.2 Extract data
Now, in order to ask ChatGPT about specifics of our story, we can create a chat with a suitable system prompt:
library(ellmer)
chat <- chat_openai(
system_prompt = "
You are an information extractor AI.
The user will give you a story and you will
provide the following information in the response:
Name of main character: <Insert name here>
Names of supporting characters: <Insert comma-
separated list of names here>
One-Sentence Summary: <Insert summary here.
Use one sentence only>
Lesson learned: <Summarize what the hero
learned in two sentences>
"
)
## Using model = "gpt-4o".And now, we can feed in the story as a user prompt.
txt_full_story <- read_lines('dat/story.txt') |>
paste(collapse = '\n')
chat$chat(txt_full_story)
## Name of main character: Dax Ironfist
##
## Names of supporting characters: Ryn
##
## One-Sentence Summary: Dax Ironfist, a reluctant inventor, chases his rogue
## automaton into ancient dwarven ruins and, alongside a young adventurer named
## Ryn, learns that his inventions have the potential to help others beyond the
## confines of his workshop.
##
## Lesson learned: Dax learns that while he has always viewed his inventions as
## personal creations, they could serve a greater purpose and contribute to
## helping others. This realization ignites a newfound sense of purpose,
## suggesting that his work could have broader impacts beyond his own safety and
## comfort.Just so that you can read the actual reply, here’s also the reply in a narrower format. Don’t worry about the code here.
chat$last_turn('assistant')@text |>
stringr::str_split_1('\n') |>
stringr::str_wrap(width = 50) |>
paste(collapse = '\n') |>
cat()
## Name of main character: Dax Ironfist
##
## Names of supporting characters: Ryn
##
## One-Sentence Summary: Dax Ironfist, a reluctant
## inventor, chases his rogue automaton into ancient
## dwarven ruins and, alongside a young adventurer
## named Ryn, learns that his inventions have the
## potential to help others beyond the confines of
## his workshop.
##
## Lesson learned: Dax learns that while he
## has always viewed his inventions as personal
## creations, they could serve a greater purpose and
## contribute to helping others. This realization
## ignites a newfound sense of purpose, suggesting
## that his work could have broader impacts beyond
## his own safety and comfort.4.3 Use a structure
Sweet. This worked pretty great. But the thing with LLMs is that we can never be sure that it will actually adhere to this specific format.
For example, it’s easy to imagine that the LLM might also add introductory sentences like “Sure, here’s your data”. That might not be great if we rely on the structure of the reply.
Enter structured outputs. With the extract_data() method, we can enforce a certain output. For that, let’s create a new chat with a shorter system prompt.
chat <- chat_openai(
system_prompt = "
You are an information extractor AI.
The user will give you a story and you will
provide the requested information in the response.
"
)
## Using model = "gpt-4o".Then, we can use the extract_data() method. Inside of this function, we can specify the so-called type. That’s the desired output format. It is specified using type_*() functions.
output_structure <- type_object(
name_main = type_string(
description = 'Name of main character'
),
name_support = type_string(
description = 'Names of supporting characters,
comma-separated list'
),
summary = type_string(
description = 'One-Sentence Summary'
),
lesson_learned = type_string(
description = 'Lesson learned, summarize what
the hero learned in two sentences'
)
)And with this, we can use the extract_data() method in combination with the story text.
chat$extract_data(
txt_full_story,
type = output_structure
)
## $name_main
## [1] "Dax Ironfist"
##
## $name_support
## [1] "Ryn"
##
## $summary
## [1] "Dax Ironfist, a reluctant dwarven inventor, chases his rogue automaton into ancient ruins, where he's helped by a young adventurer named Ryn to stop it from causing destruction."
##
## $lesson_learned
## [1] "Dax Ironfist learns that his inventions have potential beyond his personal use; they can aid others and contribute to greater causes, inspiring a newfound sense of purpose and the understanding that collaboration can lead to fulfilling and impactful results."Sweet! Now, we have an R list that we can work with.
4.4 Access the data
And in case you’re wondering how to get to the data from the chat object itself, here’s how to do it. First, you have to get the last turn.
last_turn <- chat$last_turn('assistant')
last_turn
## <ellmer::Turn>
## @ role : chr "assistant"
## @ contents:List of 1
## .. $ : <ellmer::ContentJson>
## .. ..@ value:List of 1
## .. .. .. $ wrapper:List of 4
## .. .. .. ..$ name_main : chr "Dax Ironfist"
## .. .. .. ..$ name_support : chr "Ryn"
## .. .. .. ..$ summary : chr "Dax Ironfist, a reluctant dwarven inventor, chases his rogue automaton into ancient ruins, where he's helped by"| __truncated__
## .. .. .. ..$ lesson_learned: chr "Dax Ironfist learns that his inventions have potential beyond his personal use; they can aid others and contrib"| __truncated__
## @ json :List of 8
## .. $ id : chr "chatcmpl-B957GeUYzPqCKR3qYZbuSKfx7mXhG"
## .. $ object : chr "chat.completion"
## .. $ created : int 1741504318
## .. $ model : chr "gpt-4o-2024-08-06"
## .. $ choices :List of 1
## .. ..$ :List of 4
## .. .. ..$ index : int 0
## .. .. ..$ message :List of 3
## .. .. .. ..$ role : chr "assistant"
## .. .. .. ..$ content: chr "{\"wrapper\":{\"name_main\":\"Dax Ironfist\",\"name_support\":\"Ryn\",\"summary\":\"Dax Ironfist, a reluctant d"| __truncated__
## .. .. .. ..$ refusal: NULL
## .. .. ..$ logprobs : NULL
## .. .. ..$ finish_reason: chr "stop"
## .. $ usage :List of 5
## .. ..$ prompt_tokens : int 1321
## .. ..$ completion_tokens : int 112
## .. ..$ total_tokens : int 1433
## .. ..$ prompt_tokens_details :List of 2
## .. .. ..$ cached_tokens: int 1280
## .. .. ..$ audio_tokens : int 0
## .. ..$ completion_tokens_details:List of 4
## .. .. ..$ reasoning_tokens : int 0
## .. .. ..$ audio_tokens : int 0
## .. .. ..$ accepted_prediction_tokens: int 0
## .. .. ..$ rejected_prediction_tokens: int 0
## .. $ service_tier : chr "default"
## .. $ system_fingerprint: chr "fp_eb9dce56a8"
## @ tokens : int [1:2] 1321 112
## @ text : chr ""And from there you can follow the hierarchy all the way down to wrapper deep inside the contents field. Just make sure that you use @, $ and brackets appropriately.
last_turn@contents[[1]]@value$wrapper
## $name_main
## [1] "Dax Ironfist"
##
## $name_support
## [1] "Ryn"
##
## $summary
## [1] "Dax Ironfist, a reluctant dwarven inventor, chases his rogue automaton into ancient ruins, where he's helped by a young adventurer named Ryn to stop it from causing destruction."
##
## $lesson_learned
## [1] "Dax Ironfist learns that his inventions have potential beyond his personal use; they can aid others and contribute to greater causes, inspiring a newfound sense of purpose and the understanding that collaboration can lead to fulfilling and impactful results."And of course, we could turn this thing into a tibble.
last_turn@contents[[1]]@value$wrapper |>
dplyr::as_tibble()
## # A tibble: 1 × 4
## name_main name_support summary lesson_learned
## <chr> <chr> <chr> <chr>
## 1 Dax Ironfist Ryn Dax Ironfist, a reluctant dwarven in… Dax Ironfist …4.5 Named entitity recognition
Alright, let’s do one more example. Let’s try to extract all named entities from this story. This is a common thing people want to do in text analysis.
Here, we can do this by creating another type. For now, let’s just go with name and description of the entity.
type_entity <- type_object(
.description = 'A named entity that was found
in our story',
name = type_string('Name of the entity'),
desc = type_string('One sentence description
of entity')
)But of course we don’t want to find just a single entity. We want our LLM to extract all entities. Thus, let’s make sure that we ask our LLM to extract an array (or “vector” as we’d say in the R world).
chat$extract_data(
txt_full_story,
type = type_array(
# items is the argument name of
# the array content type
items = type_entity
)
)
## name
## 1 Dax Ironfist
## 2 Ryn
## desc
## 1 A stout dwarf and reluctant inventor who creates mechanical marvels in his underground workshop.
## 2 A young, agile adventurer clad in mismatched armor who assists Dax in retrieving the rogue automaton.And as always I prefer a tibble. Here, we have multiple rows (with two columns each), so we need to use bind_rows() to turn this into a tibble.
last_turn <- chat$last_turn('assistant')
last_turn@contents[[1]]@value$wrapper |>
bind_rows()
## # A tibble: 2 × 2
## name desc
## <chr> <chr>
## 1 Dax Ironfist A stout dwarf and reluctant inventor who creates mechanical marv…
## 2 Ryn A young, agile adventurer clad in mismatched armor who assists D…4.6 Adding classification
Finally, let’s complete this example by also showing you how these types can be used for automations. The trick is to modify our type_entity with yet another entry using type_enum().
This particular type corresponds to a categorical variable. It’s what you’d call a factor in the R world.
type_entity <- type_object(
.description = 'A named entity that was found
in our story',
name = type_string('Name of the entity'),
type = type_enum(
description = 'Classification of entity',
values = c('Protagonist', 'Antagonist', 'Other')
),
desc = type_string('One sentence description
of entity')
)And with that, we can run our entity recognition again.
chat$extract_data(
txt_full_story,
type = type_array(
items = type_entity
)
)
last_turn <- chat$last_turn('assistant')
last_turn@contents[[1]]@value$wrapper |>
bind_rows()
# # A tibble: 3 × 3
# name type desc
# <chr> <chr> <chr>
# 1 Dax Ironfist Protagonist A stout dwarf inventor who prefers the safety o…
# 2 Ryn Other A young, enthusiastic adventurer clad in mismat…
# 3 Automaton Other Dax's creation, a small, gear-driven machine de…4.7 Using PDFs
Now, let’s imagine that we have a invoice as a PDF like this. This is an example I’ve fetched from Microsoft.
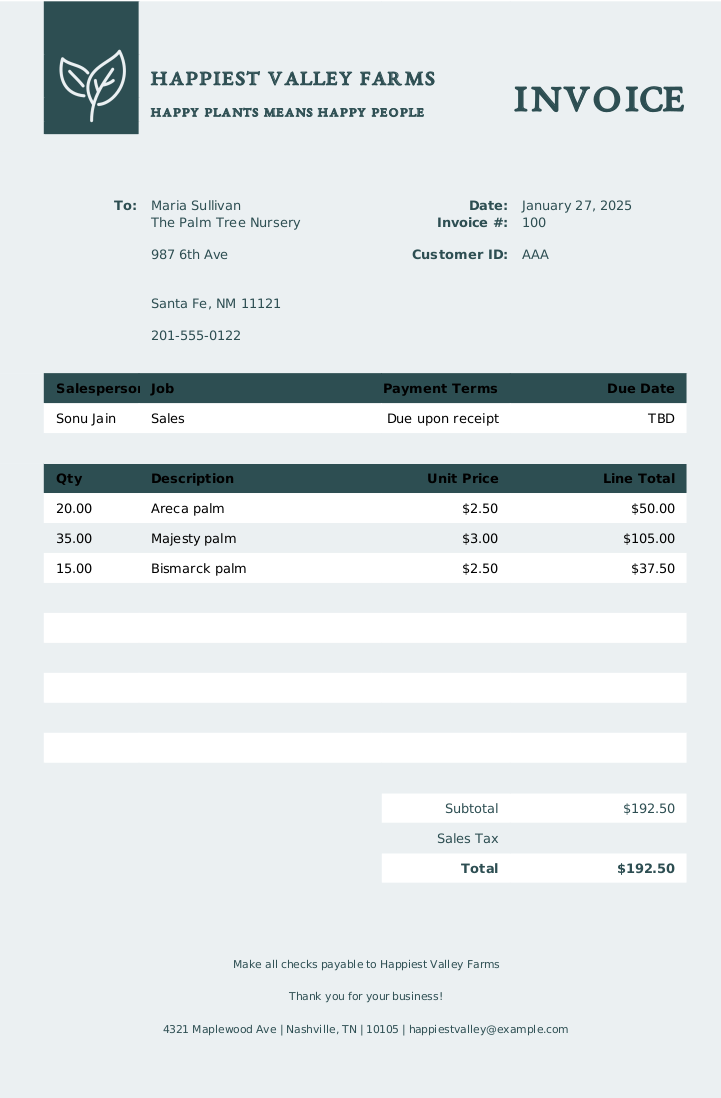
By combining what we’ve just learned about turning texts into dataframes with {pdftools} to extract text from PDFs, we can create a powerful combo. Here’s how it works. We can first extract the text using {pdftools}.
txt_pdf <- pdftools::pdf_text('dat/invoice.pdf')
## PDF error: Mismatch between font type and embedded font file
txt_pdf |>
stringr::str_wrap(width = 50) |>
paste(collapse = '\n') |>
cat()
## Happiest Valley Farms Happy plants means happy
## people Invoice To: Maria Sullivan Date: January
## 27, 2025 The Palm Tree Nursery Invoice #: 100
## 987 6th Ave Customer ID: AAA Santa Fe, NM 11121
## 201-555-0122 Salesperson Job Payment Terms Due
## Date Sonu Jain Sales Due upon receipt TBD Qty
## Description Unit Price Line Total 20.00 Areca
## palm $2.50 $50.00 35.00 Majesty palm $3.00 $105.00
## 15.00 Bismarck palm $2.50 $37.50 Subtotal $192.50
## Sales Tax Total $192.50 Make all checks payable to
## Happiest Valley Farms Thank you for your business!
## 4321 Maplewood Ave | Nashville, TN | 10105 |
## happiestvalley@example.comLooks all messed up. But no problem. AI will handle this for us.
Also note that here text extraction works pretty great as the text is also embedded in the pdf. For trickier types of PDFs (like scanned documents), you might want to resort to OCR methods. But let’s save this story for another time.
For now, let’s continue with our current example. We just have to make sure that define a custom type.
type_invoice_position <- type_object(
'A single invoice position',
position = type_string('Description of the position'),
quantity = type_number('Quantity/Number of hours'),
rate = type_number('Price per piece/Hourly rate'),
total = type_number('Total amount of invoice positon'),
currency = type_enum(
'currency of invoice position',
values = c('USD', 'EUR', 'Other')
)
)And then we can wrap that into an array and extract the data. Maybe a new chat with a new system prompt will also be good.
chat <- chat_openai(
system_prompt = '
You area an invoice extraction assistant. The user
will provide you with text from an invoice and you are
to extract every position from it.'
)
## Using model = "gpt-4o".
chat$extract_data(
txt_pdf,
type = type_array(
'List of all available invoices',
items = type_invoice_position
)
)
## position quantity rate total currency
## 1 Areca palm 20 2.5 50.0 USD
## 2 Majesty palm 35 3.0 105.0 USD
## 3 Bismarck palm 15 2.5 37.5 USDNice! So with that you should have a good idea of how structured outputs work. If you’re looking for more examples, then the {ellmer} docs have a few more fantastic examples.


